EN / HY 500: Digital Humanities Spring 2015
Paper Machines: Organize and Analyze Research
Tool Name: Paper Machines
Version Number/Release Date: Paper Machines Version 0.4.9
Developer Website: http://papermachines.org/
Reviewed by: D. Geoffrey Emerson
Review Date: 2/7/15
Tags or Keywords: Topic Modeling, N-grams, Word Cloud, Mapping, Phrase Net, Annotation, Bibliography
General Purpose of Tool: Paper Machines provides a textual collection with textual analysis based on Zotero’s ability to collect bibliographic data from the web. As a plug-in for Zotero, Paper Machines converts pdf documents into a format that analyzes the textual data and provides a range of tools with which to analyze the collection.
Review:
Paper Machines is a Digital Humanities toolkit that provides users with the opportunity to explore the textual data of a user created bibliographic collection. The toolkit has a range of options that visualize the language and concepts shared across the texts representing them over time, geographically, or spatially to uncover commonalities, variation, or coherence. Paper Machines offers the following tools:
- Word Cloud
- N-grams
- Phrase Net
- Mapping
- DBPedia
- Topic Modeling
Word Cloud is a common tool with which to investigate textual data. The tool generates a connection of the most commonly used words in a given corpus, with the option to remove unwanted grammatical constructions. The terms that occur with more frequency appear larger than these that appear less often.

N-grams allow users to search words and track their usage over time. The program represents the frequency with which a certain word or words is used with a line graph. If a corpus that a user investigates spans a long periods of time, they can track how specific concepts go in and out of style.
[Image taken from: http://googleresearch.blogspot.com/2012/10/ngram-viewer-20.html]
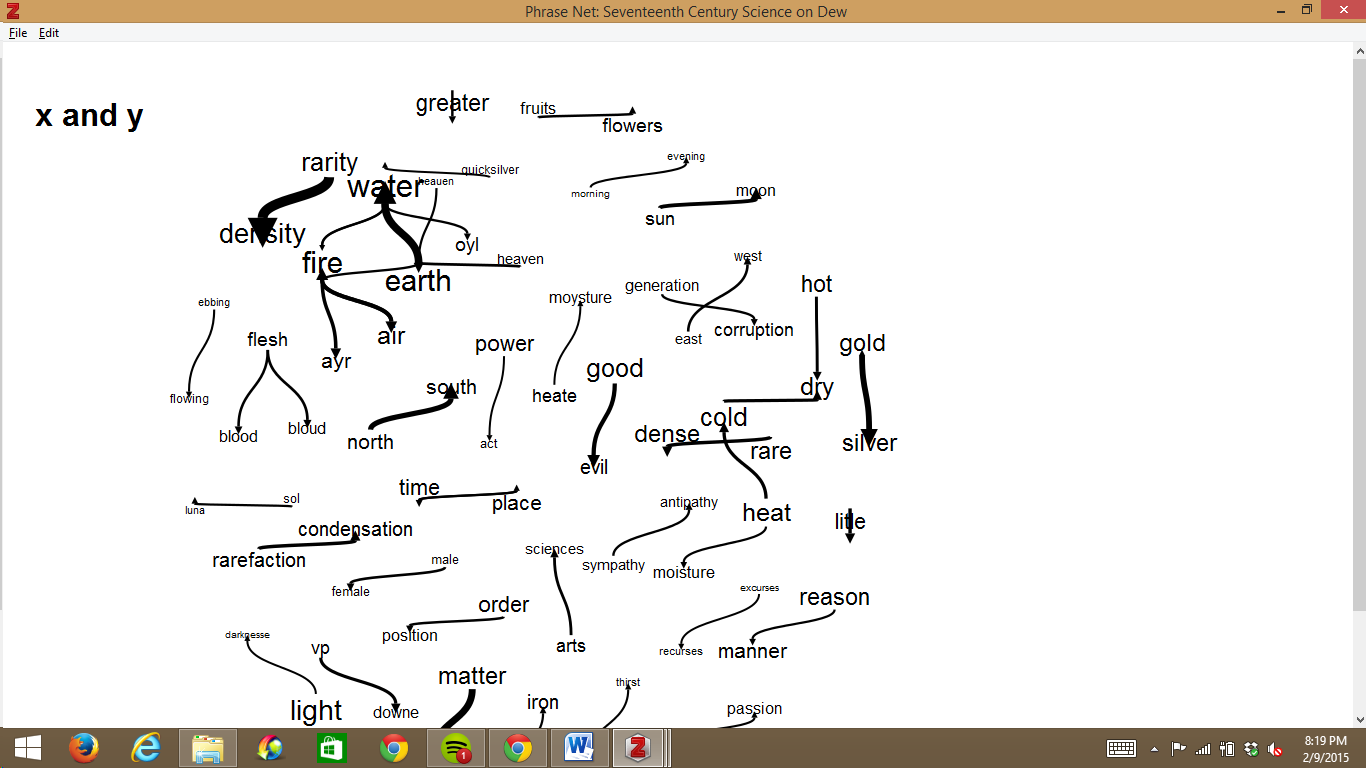
Phrase Net offers a number of concept relationships through which users can visually represent the correspondence of a limited number of concepts. Relationships include “x and y,” x or y,” “x of the y” etc. This tool allows users to track the relationships between common concepts across the designated texts.
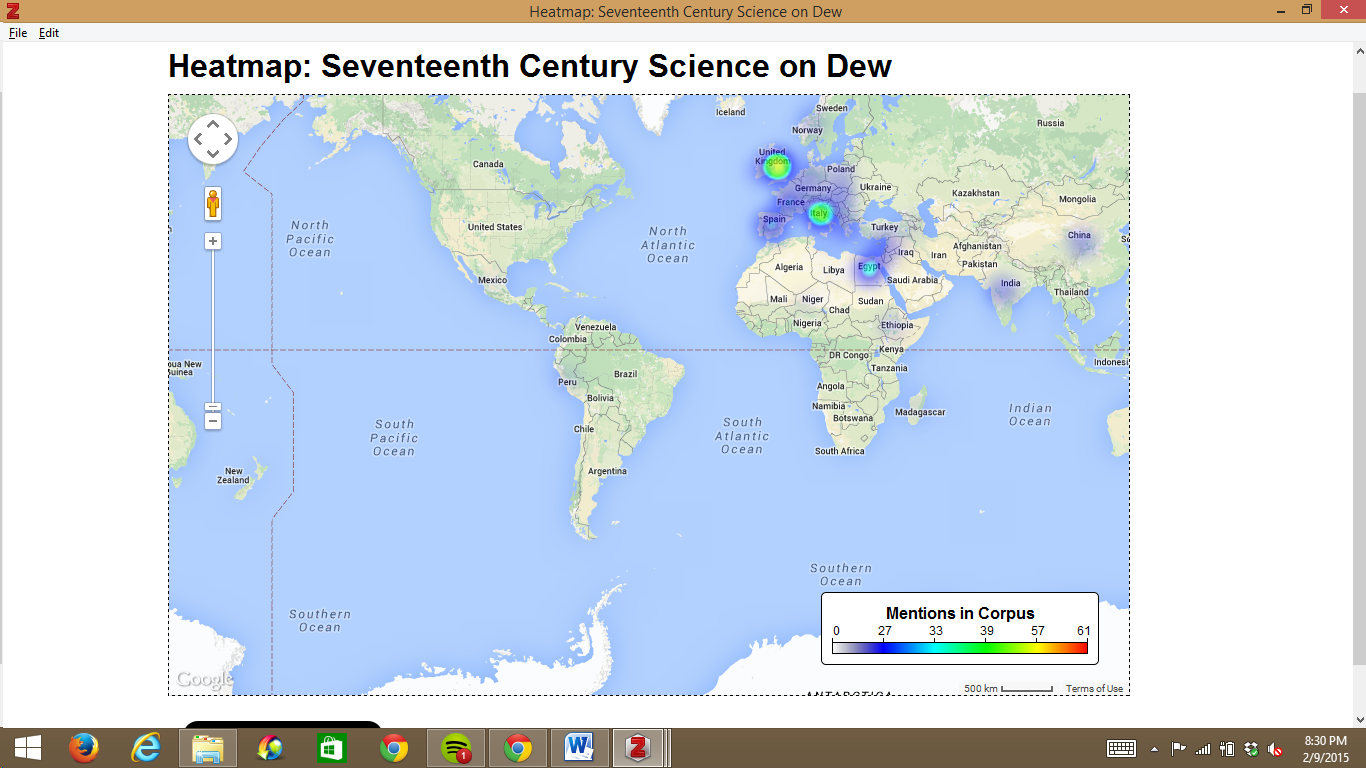
Mapping is another common tool that tracks both geographical references and bibliographic information collected by Zotero. Paper Machines can generate either a heat map or a flight map or export the geodata to a CSV.
DBPedia offers an annotation database of named entities in the corpus scaled to frequency. Users can investigate unfamiliar texts for frequently occurring entities thereby discovering the most influential people, organizations, or concepts.
Topic Modeling maps the texts for frequently recurring strings of concepts. It allows users to see how specific topics instantiated in three word sequences weave through the texts in the collection.

Users begin by downloading the relevant applications and plug-ins, I chose the Chrome Zotero plug-in to collect my bibliographic data which transferred my collection to the Zotero standalone application in which I installed the Paper Machines plug-in. Once I gathered the bibliographic data for my collection from the Early English Books Online database, I uploaded PDF texts of the raw text. After which I was able to right-click on the collection, extract text for Paper Machines, and select the tool that I wish to use.
Paper Machines successfully offers users an array of Digital Humanities tools in an easy to use interface. While there is a learning curve and some of the process is unclear even after reading the Paper Machines literature, users need no knowledge of the complex computational models behind MALLET, Many Eyes, and other Digital humanities technologies. As a plug-in for the Zotero application, Paper Machines is both powerful and convenient. It combines the bibliographic collection and organization of Refworks with the textual analysis tool suit of Many Eyes and Voyant Tools. Much of the bibliographic collection process is automated, and works directly through an internet browser. The text file uploading that provides the textual analysis toolkit with data is intuitive overall, but requires some trial and error.
The toolkit detailed above is versatile and useful for Digital Humanities textual analysis. The toolkit provides users with an array of interpretive and visualization options powered by impressive Digital Humanities technology. The Word Cloud, N-grams, Phrase Net, and Topic Modeling enable users to investigate a collection of texts by visualizing conceptual relationships that may yield discoveries in a long dead discourse, or provide a lineage for relevant contemporary issues. The Mapping tools provide geo-political context, while the DBPedia provides an opportunity to dig into the content and references that appear in the body of texts.
Zotero works with any browser the user prefers, but the Paper Machines plug-in only works for the Zotero stand-alone application, or the Firefox browser plug in. These restrictions are disappointing, but these programs may provide the program with necessary infrastructure. Further, despite the convenience of the bibliographic tool and the user friendly toolkit, the program does require a considerable time investment on the part of the user. Like many tools and technologies in Digital Humanities, interested parties are compelled to “feel” their way through new approaches and commit to learning not only new technology, but new types of literacy.
Although there I presume there are good reasons for many of the choices behind Paper Machines, there is one major drawback: a lack of supporting information. While Paper Machines offers an impressive array of options, the application’s website offers little guidance. The “How to Use Paper Machines” page is vague, only providing limited information about each tool and nothing for beginners who may not know how to interpret the visualizations. To make the program easy to use, much of the computational methodology is not immediately accessible. Users can find some information on the website, or the internet more broadly, but it doesn’t offer much more than generalities about how these types of tools function. In addition, when a tool does not work—I, for instance, could not get N-grams to work—there was no identifiable troubleshooting guide from the developers so I was left changing parameters hoping that the tool would work. This process leaves something to be desired, I had a vague idea of how I would affect the outcome, but the lack of certainty was disconcerting.
Overall, Paper Machines offers a versatile and powerful toolkit for its users. Despite the minor frustrations and a significant time investment, the suit of tools is user friendly, cutting out much of the technical knowledge base required by the technology that undergirds the program. The toolkit does, however, lend itself to certain types of projects, though I think it is less exclusive than it initially appears. Paper Machines offers its users the ability to analyze vast amounts of textual data, but the distance reading techniques only provide context. The two main uses for Paper Machines, then, is a survey of critical discourse, or generating a discursive historical collection in which to situate the user’s project. I do, however, believe that it is more useful that it appears. While the results generated by the toolkit may or may not make it into published versions of the users’ project, minimally I think it is invaluable during conceptual and exploratory phases of any project. In addition, I was not able to explore the full potential of the program here, so while the developers continue to improve the technology; the possible applications for these Digital Humanities tools is may only be beginning.
Comparable Tools:
Textual Analysis Toolkits:
Many Eyes: http://www-01.ibm.com/software/analytics/many-eyes/
Voyant Tools: http://voyant-tools.org/
Topic Modeling:
MALLET: http://mallet.cs.umass.edu/index.php
Bibliographic Collection:
Refworks: https://www.refworks.com/
Other Reviews:
Journal of Digital Humanities:
http://journalofdigitalhumanities.org/2-1/review-papermachines-by-adam-crymble/
Chronicle of Higher Education:
http://chronicle.com/blogs/profhacker/paper-machines-visualizes-your-zotero-library/44056